
🎯 Episode 12: AI interview-Choosing the Right Metric — How to Justify Accuracy, F1 or AUC in an Interview

Great models die on the wrong scoreboard.
In interviews, saying “I used accuracy” without a reason is the fastest way to look junior.
This episode gives you a practical decision framework for picking evaluation metrics, plus the language that convinces interviewers you know why a metric matches the business goal.
🧭 1. Start With the 3-Question Framework
What’s the business cost of each error?
False‐positives vs false‐negatives?How is the data shaped?
Imbalanced classes? Continuous targets? Ranked lists?How will the model be used?
Thresholded rule, top-k ranking, probability feed-through, or human-in-the-loop?
If you answer those, the right metric nearly picks itself.
📊 2. Binary Classification — Accuracy ≠ Enough
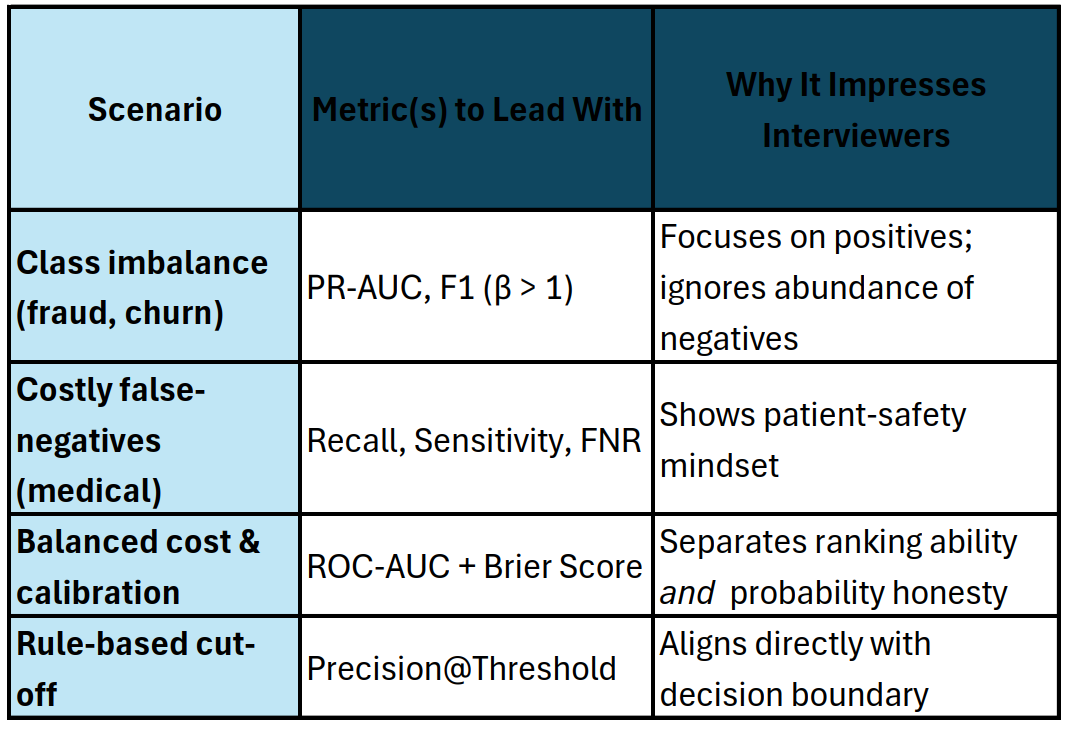
Interview sound-bite:
“The dataset is 1 % fraud, so I optimised PR-AUC and reported F1; accuracy would be 99 % just predicting ‘not fraud’.”
🎨 3. Multiclass & Multilabel Classification — Macro vs Micro
Macro F1 / Fβ → Treats each class equally (good for imbalance).
Micro F1 → Aggregates over samples (good when classes balanced).
Top-k Accuracy → When UI shows multiple suggestions (OCR, image tagging).
Hamming Loss → For multilabel: penalises each wrong label independently.
Interview tip: justify which averaging you used.
📈 4. Regression & Forecasting
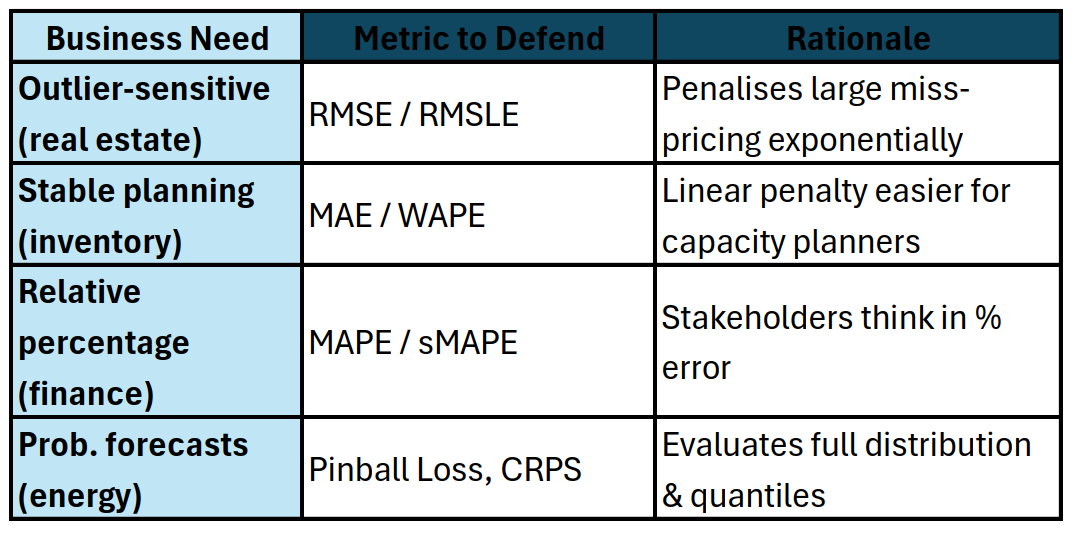
One-liner:
“MAE was chosen because a $5 forecast miss is equally painful whether demand is 20 or 200 units.”
🔎 5. Ranking / Search / Recommenders
nDCG – discounts lower-rank hits; great for SERPs.
MAP / MRR – clearer for academic datasets.
Hit Rate@k / Precision@k – business communicates “how many top-10 slots did we nail?”.
Serendipity / Novelty – show you understand user delight.
Quote in interview:
“We tuned for nDCG@10 because user clicks concentrate in the top results.”
🖼️ 6. Computer Vision
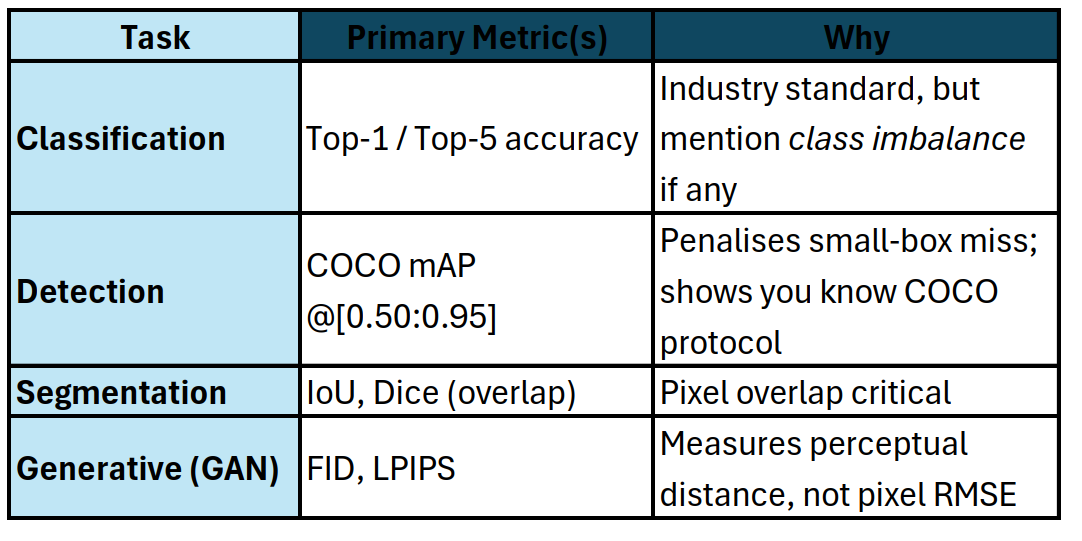
📚 7. NLP & LLMs
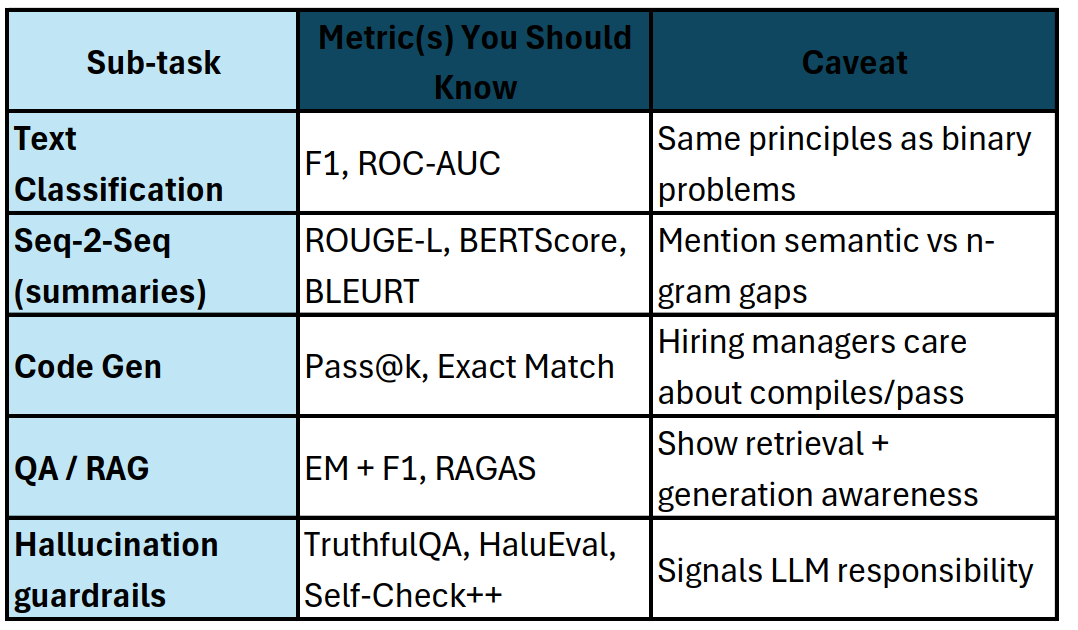
Talking point:
“BLEU looked fine, but BERTScore exposed semantic misses; we optimised with sentence-level loss.”
🧪 8. Calibration & Uncertainty Metrics
Brier Score – mean squared prob. error.
ECE / MCE – bin-based gap between confidence & accuracy.
Prediction Interval Coverage (PICP) – time-series interval reliability.
Explain like:
“High ROC-AUC but poor ECE told us the probabilities were over-confident, so we applied temperature scaling.”
🌍 9. Fairness Metrics
When a recruiter asks “how do you test for bias?”:
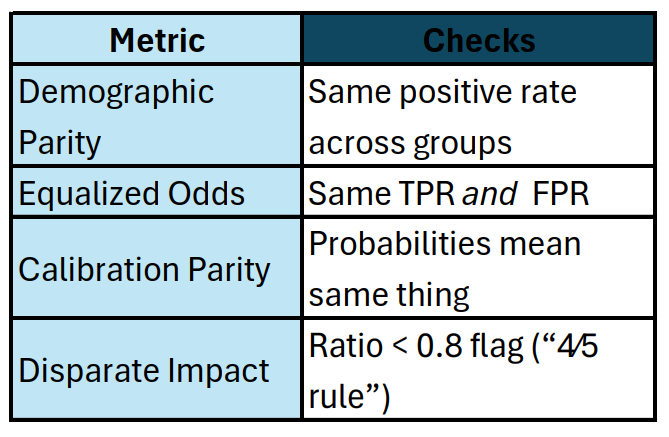
Pro phrase:
“Accuracy stayed flat but equalized odds improved after reweighting — that’s a win.”
🤖 10. When You Truly Can Use Accuracy
Balanced classes and symmetric cost of errors.
Early prototyping to sanity-check pipeline.
Post-threshold business rule already drives decision cost.
But always be ready to defend why you didn’t use F1, AUC, etc.
🧠 11-Step Metric Decision Cheat Sheet
Define business cost matrix.
Check class/label balance.
Binary / multi / rank / regression?
Need calibrated probabilities?
Is threshold fixed or flexible?
Human-in-the-loop or full automation?
Any regulatory fairness constraints?
Does latency push you to specific metrics (e.g., Top-k)?
For DL, monitor BOTH loss & deployment metric.
Plot confusion matrix or residuals — visual sanity.
Document why alternative metrics were rejected.
🗨️ Interview Phrases That Land
“We optimised PR-AUC because positives are rare, and F1 (β = 2) aligned with business recall goals.”
“RMSE inflated outliers; stakeholders cared about average dollar miss, so MAE made decisions clearer.”
“We reported nDCG@10 — that maps exactly to a user scrolling a mobile screen.”
Use one and watch interviewers nod.