
🎯 Episode 13: AI interview-Understanding Class Imbalance — The Hidden Interview Trap

Your model claims 99 % accuracy…
The recruiter smiles, then asks: “How many positive examples were in the data?”
If you can’t answer — or worse, you didn’t check — the interview just ended.
Class imbalance shows up in fraud detection, rare-disease screening, churn modeling, spam filtering, and safety-critical vision systems. Today we’ll arm you with the knowledge (and language) to impress any panel.
1. What Exactly Is Class Imbalance?
Definition: One or more target classes constitute a small fraction of the data (often ≪ 10 %).
Consequence: Standard metrics (especially accuracy) get inflated because the model learns to predict the majority class.
Quick sanity check
from collections import Counter
print(Counter(y_train))
If the positive class is < 1 : 10, you’re in imbalance territory.
2. Why Interviewers Care
Real-world prevalence — Most production problems aren’t 50/50.
Risk exposure — False negatives in minority class can be costly (fraud, cancer).
Signals maturity — Good candidates discuss data distribution before model tuning.
3. Metrics That Expose Imbalance
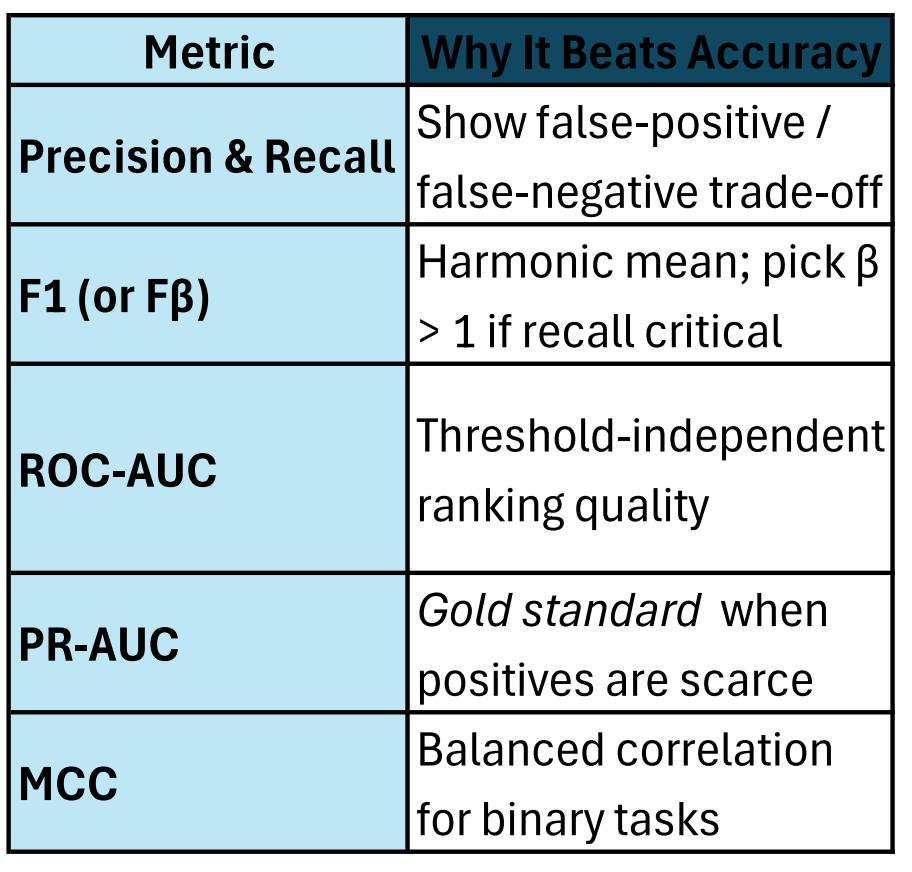
Interview line: “Accuracy was 99 %, but PR-AUC was only 0.17 — the model just predicted not-fraud.”
4. Core Techniques to Handle Imbalance
A. Resampling the Training Set
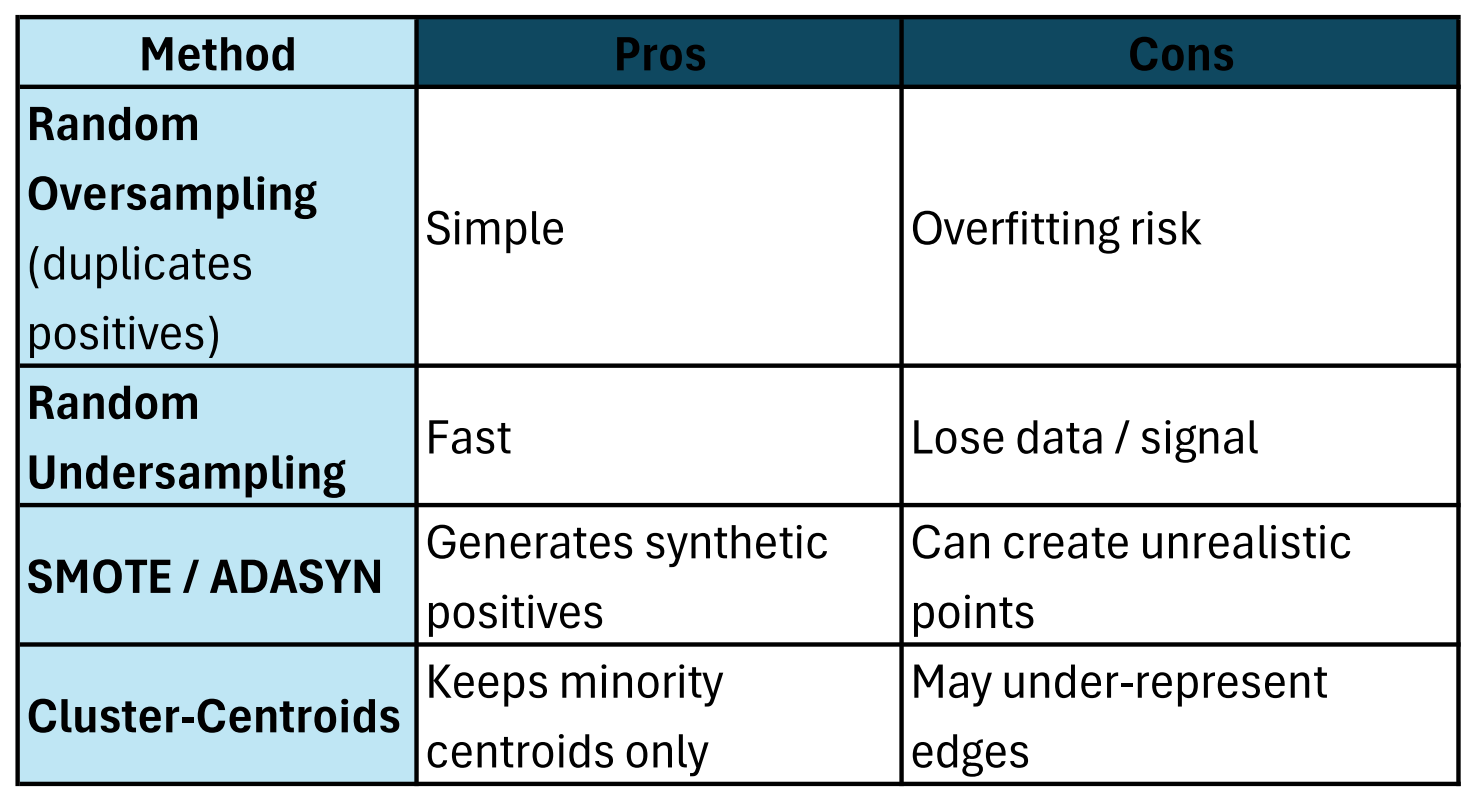
Interview tip: “I oversampled only the train fold, never the validation set — avoids optimistic bias.”
B. Algorithm-Level Fixes
Class weights / cost-sensitive loss
class_weight='balanced'insklearn, orpos_weightin PyTorch BCE.Focal Loss — down-weights easy majority examples (vision, detection tasks).
Threshold tuning — pick operating point via ROC or PR curve.
C. Ensemble Tricks
Balanced Random Forest / EasyEnsemble — build each tree on balanced bootstrap.
Gradient Boosting with sample weights — XGBoost’s
scale_pos_weight.
5. Walk-Through Example (Fraud 0.2 %)
from imblearn.over_sampling import SMOTE
from xgboost import XGBClassifier
from sklearn.metrics import average_precision_score
X_res, y_res = SMOTE().fit_resample(X_train, y_train)
model = XGBClassifier(scale_pos_weight=100, eval_metric='aucpr')
model.fit(X_res, y_res)
probs = model.predict_proba(X_valid)[:,1]
print("PR-AUC:", average_precision_score(y_valid, probs))
Explain this pipeline in an interview and you’ll score immediate credibility.
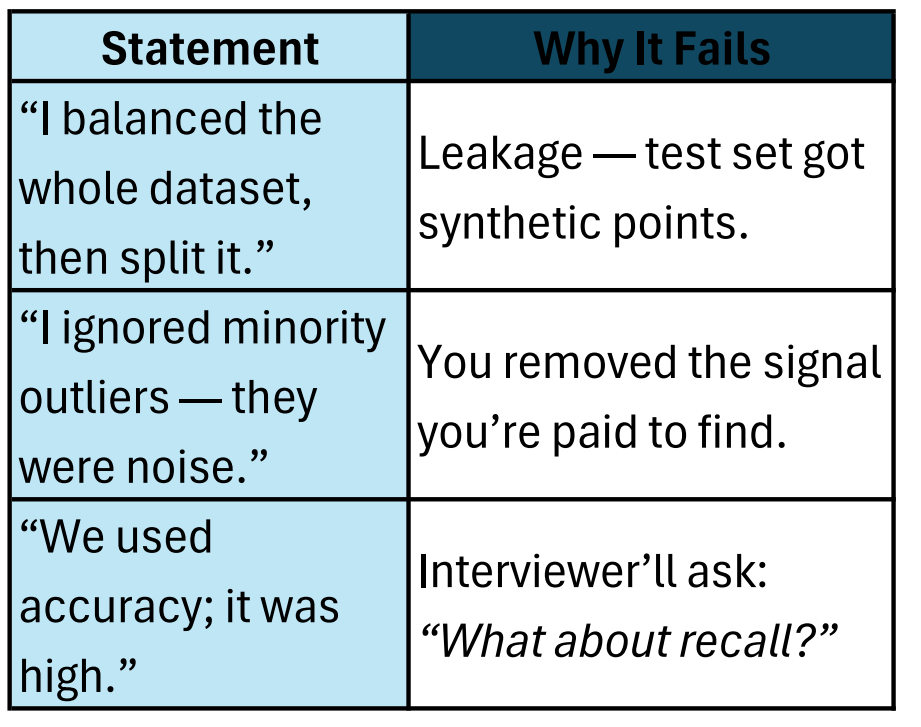
6. Common Pitfalls You Must Avoid Saying
7. Interview-Ready Sound Bites
Definition
“Imbalance means one class dominates, so naïve accuracy is misleading.”
Metric Choice
“I optimise PR-AUC and F1 because positives are < 1 %.”
Technique
“We used SMOTE inside each CV fold plus class-weighted XGBoost — recall jumped from 0.12 → 0.61.”
Business Tie-In
“Catching one extra fraudulent transaction saves $500; missing one costs $50 k, so recall matters more than precision.”
8. Cheat-Sheet: When to Use What
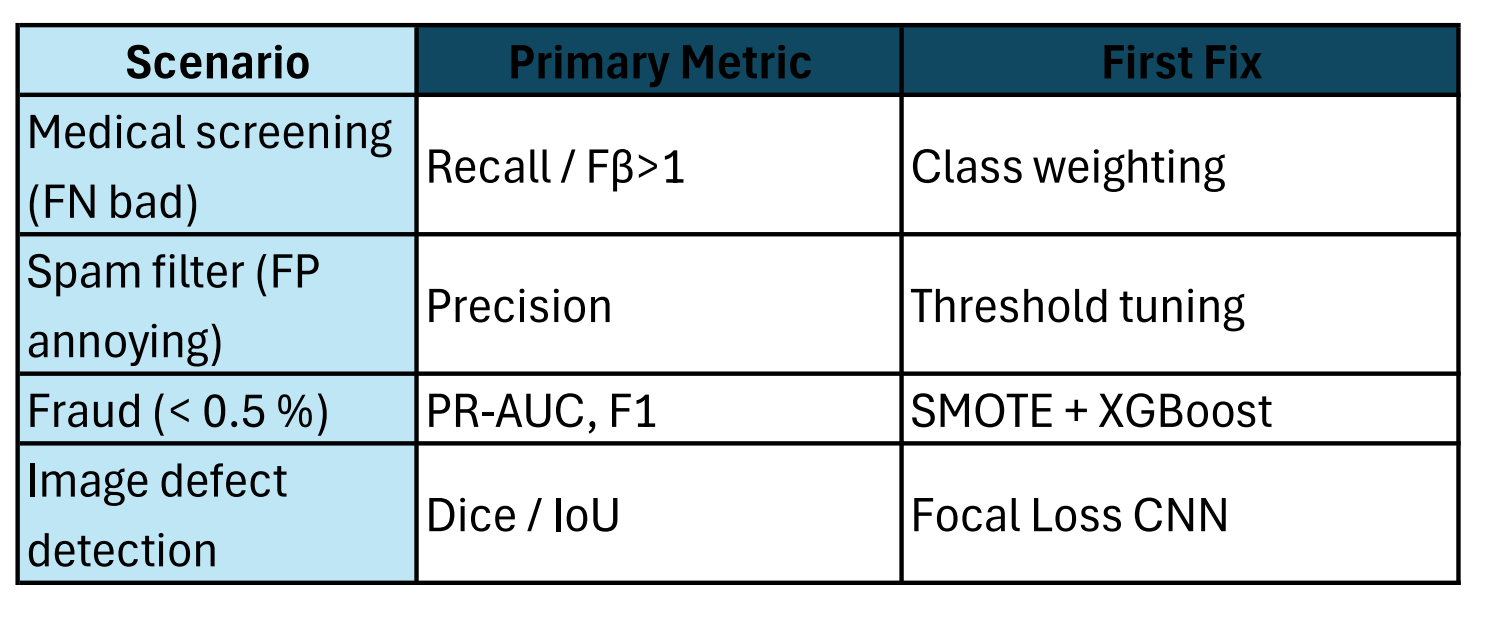
Memorise one row; interviewers love domain-specific answers.
9. Implementation Nuggets
imblearn(pip install imbalanced-learn) → SMOTE, ADASYN, EasyEnsemble.class_weight='balanced'→ everywhere insklearn, pluscompute_class_weighthelper.XGBoost:
scale_pos_weight = (neg / pos)heuristic.PyTorch BCE loss:
pos_weight = torch.tensor([neg/pos]).